Moving from Azure.AI.OpenAI to Semantic Kernel 1.0: implementing ODataAutoPilot (with video)
What is Semantic Kernel, and what is it not? A comparison using a real life scenario from a developers perspective

I am a cloud-native developer at the international university of applied sciences, working mostly with Microsoft technology
Introduction
As someone who is using LLM APIs for Bots and Apps from the very beginning of 2023, i am always looking to make my work more easy and error-resistant. Now i've come around yet another problem i wanted to solve with the help of an LLM, and coincidently version 1 of Semantic Kernel released, which gives the great opportunity to do a side-by-side comparison.
The libraries
My tool-of-choice was the Azure.AI.OpenAI lib so far, which is a wrapper for the OpenAI Endpoint both from OpenAI themselves as well as the Azure hosted version.
You can learn more about that here.
The new contender is Microsoft.SemanticKernel (will be referred to as SK from now on because its a mouthful). If you ever thought "Wouldn't it be cool to have one Library that can work with all the LLMs out there, without me having to implement everything myself" then you found your solution here. On top of the many connectors (even local models!) SK provides something else: People reading current papers on new advancements on how to utilize LLMs the best way and implementing that as code. And now those people are from Microsoft, preparing and testing the code, letting you put more time into solving your actual problems instead of working on the LLM layer. Yes i am biased because i am excited.
You can learn more about SK here
The problem to solve
(you can skip this if you want only migration hints towards SK)
One of my latest pet projects was "what if i do not design a database to save data, but give an ODATA Endpoint to the LLM so it can figure out the data structure by itself?". I will cover this "AI-as-a-Backend" experiment in a later blogpost.
For now, we have an Azure Table with a ODATA Endpoint which was filled by the LLM via this function / plugin / extension / tool / skill / whatever your tech stack calls it:
[SKFunction, Description(@"Sends a GET, PUT, PATCH or DELETE to an azure Table ODATA endpoint.
The final URL will look like this: 'https://account.table.core.windows.net/{tableName}{oDataParameters}'
")]
public string RunOdata(
[Description("the name of the Azure Table")] string tableName,
[Description(@"The parameters of the ODATA url after the tablename, for example: '?$filter=Name eq 'Alice'' for a GET with filter,
'(PartitionKey='p1',RowKey='r1')' for PATCH, PUT and DELETE")] string oDataParameters,
[Description("GET, PATCH, PUT or DELETE")] string method,
[Description("In case of PATCH and PUT, this is the body to use in the HTTP request")] string PostEntityData = "")
{
HttpClient client = new HttpClient();
string url = $"https://account.table.core.windows.net/{tableName}{oDataParameters}";
string sasToken = Environment.GetEnvironmentVariable("Table_SAS_Token");
if (url.Contains("?"))
{
url += "&" + sasToken;
} else
{
url += "?" + sasToken;
}
// Set the date and version headers
string datetimeNow = DateTime.UtcNow.ToString("R", System.Globalization.CultureInfo.InvariantCulture);
client.DefaultRequestHeaders.Add("x-ms-date", datetimeNow);
client.DefaultRequestHeaders.Add("x-ms-version", "2015-04-05");
// Construct the entity data as a JSON string
string entityData = PostEntityData;
HttpMethod httpMethod = new HttpMethod(method);
HttpRequestMessage req = new HttpRequestMessage(httpMethod, url);
if (!string.IsNullOrEmpty(entityData))
{
req.Content = new StringContent(entityData, Encoding.UTF8, "application/json");
}
// Send the POST request and get the response
HttpResponseMessage response = client.Send(req);
// Check the status code and print the result
if (response.IsSuccessStatusCode)
{
// Read the response content as a string
string result = response.Content.ReadAsStringAsync().Result;
return result;
}
else
{
return ($"{response.StatusCode} {response.ReasonPhrase}");
}
}
Together with some system prompting on how to use this table and what columns should be used this was working okay. The database is saving data on when a baby was fed. As atomic information, this was collected:
-Name of parent
-amount of milk
-Date and time
I've had some trouble to get DateTimes working, because Azure Table only accepts UTC in ISO 8601 format ("2023-12-09T11:30:00Z"), and doing UTC to CEST conversion via the System Prompt was not my first approach, so i opted for 4 Columns instead: Month, Day, Hour, Minute. This had another problem: if not specified which month a query is about, the LLM would just hallucinate that. Using one DateTime does reduce the halucination risk greatly. So i had to find a way reducing the 4 columns into one DateTime column and bite the bitter apple to get the LLM working with UTC and CEST.
ODataAutoPilot
But how would i do this in a live database? Well, the data came in by an LLM, so why not alter it via LLM. Thus, ODataAutoPilot was born. The idea is to chat with the database, demanding changes in the process, that are executed via the ODATA Endpoint.
Here is where i can compare Azure.Ai.OpenAI and SK. Futhermore, this is a good basis for exploring more SK options afterwards.
What we need is the same generic ODATA (native) Function with the appropriate credentials. I opted for using SAS Tokens, as they free me from manually creating a Bearer Token to access the Azure Table service.
The main loop is simple:
-Ask for a user input
-give a history, the input from the user and the function to the LLM
-inner loop: call the LLM, and do so until they don't want to use a function anymore
-add the LLM output and the User Input to the history
-repeat until happy.
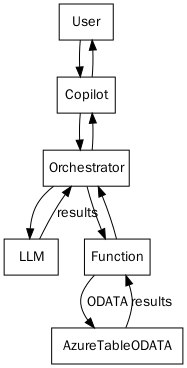
The System Message is simply this:
You are an assistant named 'ODataAutoPilot' that helps the user run ODATA commands. For this you have a function to use. Before running anything dangerous (a PUT, PATCH or a DELETE) answer the user with a summary of the parameters you want to use on the function and wait for their approval
Solved with Azure.Ai.OpenAI
Lets start with the "old", "native", "legacy", Azure.Ai.OpenAI approach.
To use functions (looks like they are called "Tools" now), Azure.Ai.OpenAI requires us to create a big fiddly JSON: Azure OpenAI client library for .NET - Azure for .NET Developers | Microsoft Learn
For prototyping and refactoring, this is a nightmare. Not only do you have to take care of the arguments one by one, you also have to map the "functioncall" the LLM wants you to do, to an actual function, and deserialize the arguments into a usable format.
The main loop is still as simple as it sounds:
private static async Task RunWithNativeAzureOpenAI(string autopilotSystemMessage)
{
AzureTableODataPlugin odata = new AzureTableODataPlugin(oDataEndpoint, sasToken);
AzureTableOdataCleaner cleaner = new AzureTableOdataCleaner();
LLMFunctionOrchestrator airunner = new LLMFunctionOrchestrator(cleaner);
airunner.LoadFromObjects(odata);
ChatRequestMessage systemMessage = new ChatRequestSystemMessage( autopilotSystemMessage);
List<ChatRequestMessage> messages = new List<ChatRequestMessage> { systemMessage };
Console.Clear();
Console.WriteLine("Welcome to ODataAutoPilot. As a suggested first step ask for the first item in a table to make the schema known. Type 'exit' to exit");
string lastInput = string.Empty;
do
{
Console.Write("User: ");
lastInput = Console.ReadLine();
messages.Add(new ChatRequestUserMessage(lastInput));
await airunner.Orchestrate(messages, client, 10,
text => { Console.WriteLine("Assistant: " + text); },
msg => { messages.Add(msg); },
logmsg => { Console.WriteLine("System: " + logmsg); });
ReduceContextSize(messages); //deliberately async, because you cant read and write faster than the cleanup happens
} while (lastInput != "exit");
}
But wait, what is that, LLMFunctionOrchestrator? As easy as the loop looks like, i have to use a helper class to not get mad with constructing functions ("tools"), calling the LLM with'em, waiting for all functions to be called that shall be called, and outputting the results in the meantime. Interestingly enough the SK team came to a very similar approach as me using reflection.
Here it is (i wont blame you if you just scroll past it, its a lot):
using Azure.AI.OpenAI;
using Json.Schema.Generation.Intents;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Linq;
using System.Reflection;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using System.Xml.Linq;
namespace CaseWorkerShared.Helper
{
public class LLMFunctionOrchestrator
{
Dictionary<ChatCompletionsFunctionToolDefinition, object> toolsToObject = new();
private readonly IDataCleanuper dataclleaner;
public void LoadFromObjects(params object[] objs)
{
foreach (object obj in objs)
{
var functions = GetFromClass(obj.GetType());
foreach (var func in functions)
{
toolsToObject.Add(func, obj);
}
}
}
public LLMFunctionOrchestrator(IDataCleanuper dataclleaner = null)
{
this.dataclleaner = dataclleaner;
}
private List<ChatCompletionsFunctionToolDefinition> GetFromClass(Type type)
{
List<ChatCompletionsFunctionToolDefinition> toolDefinitions = new List<ChatCompletionsFunctionToolDefinition>();
// Get all public instance methods
MethodInfo[] methods = type.GetMethods(BindingFlags.Public | BindingFlags.Instance);
// Get the parameter descriptions
// Iterate over each method
foreach (MethodInfo method in methods)
{
ChatCompletionsFunctionToolDefinition definition = new ChatCompletionsFunctionToolDefinition();
definition.Name = method.Name;
// Check if the Description attribute is defined for this method
if (Attribute.IsDefined(method, typeof(DescriptionAttribute)))
{
var descriptionAttribute = (DescriptionAttribute)Attribute.GetCustomAttribute(method, typeof(DescriptionAttribute));
definition.Description = descriptionAttribute.Description;
ParameterInfo[] parameters = method.GetParameters();
// Iterate over each parameter
var propertiesDict = new Dictionary<string, object>();
foreach (var parameter in parameters)
{
DescriptionAttribute parameterDescriptionAttribute = (DescriptionAttribute)Attribute.GetCustomAttribute(parameter, typeof(DescriptionAttribute));
propertiesDict.Add(parameter.Name, new
{
type = parameter.ParameterType.Name.ToLower(),
description = parameterDescriptionAttribute.Description + (parameter.IsOptional ? "(optional)" : "")
});
}
var jsonObject = new
{
type = "object",
properties = propertiesDict,
required = parameters.Where(p => !p.IsOptional).Select(p => p.Name).ToList()
};
string jsonString = JsonSerializer.Serialize(jsonObject);
definition.Parameters = BinaryData.FromString(jsonString);
toolDefinitions.Add(definition);
}
}
return toolDefinitions;
}
private string Call(object instanceToCall, string name, Dictionary<string, string> arguments)
{
// Get the type of the instance
Type type = instanceToCall.GetType();
// Get the method by its name
MethodInfo method = type.GetMethod(name);
ParameterInfo[] parameters = method.GetParameters();
// Prepare the arguments for the method call
object[] methodArguments = new object[parameters.Length];
for (int i = 0; i < parameters.Length; i++)
{
string parameterName = parameters[i].Name;
if (arguments.ContainsKey(parameterName))
{
methodArguments[i] = arguments[parameterName];
}
else
{
methodArguments[i] = Type.Missing;
}
}
// Call the method using reflection
string result = (string)method.Invoke(instanceToCall, methodArguments);
if(dataclleaner != null)
{
try
{
result = dataclleaner.Cleanup(result);
}catch(Exception ex) { //this is okay, we tried, but the LLM will still get an answer, even though its unnecessarily big
}
}
return result;
}
public async Task Orchestrate(List<ChatRequestMessage> initialMessages, OpenAIClient client, int maxFunctionChain,
Action<string> TextToUser, Action<ChatRequestMessage> MessageToPersist, Action<string> log = null)
{
int step = 0;
var tools = toolsToObject.Keys.ToList();
List<ChatRequestMessage> messages = initialMessages.ToArray().ToList(); //clean copy
ChatChoice choice;
do
{
//foreach(var damagedMessage in messages.Where(m=> m== null))
//{
// damagedMessage.Content = "";
//}
ChatCompletionsOptions options = new ChatCompletionsOptions("gpt-4-turbo", messages);
foreach (var tool in tools) {
options.Tools.Add(tool);
}
Azure.Response<ChatCompletions> result = await client.GetChatCompletionsAsync(options);
choice = result.Value.Choices[0];
if (choice.Message.Content != string.Empty)
{
TextToUser(choice.Message.Content);
}
var assistantMsg = new ChatRequestAssistantMessage(choice.Message.Content);
if (choice.Message.ToolCalls != null)
{
foreach (var toolCall in choice.Message.ToolCalls) {
assistantMsg.ToolCalls.Add(toolCall);
}
}
MessageToPersist(assistantMsg);
messages.Add(assistantMsg);
if (choice.FinishReason == CompletionsFinishReason.ToolCalls)
{
//LLM actually wants to run a tool that we offered
foreach(var toolCall in choice.Message.ToolCalls)
{
var toolFunctionCall = toolCall as ChatCompletionsFunctionToolCall;
Dictionary<string, string> arguments = JsonSerializer.Deserialize<Dictionary<string, string>>(toolFunctionCall.Arguments);
string argumentsJson = JsonSerializer.Serialize(arguments);
log?.Invoke("The LLM wants to call this function: " + toolFunctionCall.Name + ", " + argumentsJson);
var toolToCall = tools.First(f => f.Name == toolFunctionCall.Name);
object instance = toolsToObject[toolToCall];
string callResult = Call(instance, toolToCall.Name, arguments);
if (string.IsNullOrEmpty(callResult)) callResult = "no result text";
log?.Invoke("The result of the function is: " + callResult);
ChatRequestToolMessage toolMsg = new ChatRequestToolMessage(callResult, toolCall.Id);
MessageToPersist(toolMsg);
messages.Add(toolMsg);
}
}
step++;
} while (choice.FinishReason == CompletionsFinishReason.ToolCalls && step < maxFunctionChain);
}
}
public interface IDataCleanuper
{
public string Cleanup(string data);
}
}
So what happens here?
The LLMFunctionOrchestrator takes an IDataCleaner (discussed later), and waits for you to load a function by object. That object needs to have its methods decorated with [Description] to be available. Why an object and not a Type? Because you can initialize objects with a constructor, already setting up parameters. This could also be solved with dependency injection, but that was out of scope here.
Next, the Orchestrate method does the grunt work. It has yet another loop, this time looping until the LLM does not want to run a function anymore, or until the maximum function calls in a row are exceeded (security feature for my wallet). The function (tool) to call is taken from the LLMs response, the arguments are extracted and the function within the object is called. The result from that is fed back to the LLM to see if they want to do anything further.
Meanwhile there are 3 Actions exposed: one for system logging, one to talk to the user in the frontend, and one to persist messages outside of the loop (discussed later as well).
So there we have it, 200 lines of unperfect code, albeit easily copy&pastable code.
Solved with Semantic Kernel
Now lets look at SK. The main loop looks similar:
private static async Task RunWithSemanticKernel(string autopilotSystemMessage)
{
AzureTableODataPlugin odata = new AzureTableODataPlugin(oDataEndpoint, sasToken);
var builder = Kernel.CreateBuilder();
builder.AddAzureOpenAIChatCompletion("gpt-4-turbo", client);
builder.Plugins.AddFromObject(odata);
Kernel kernel = builder.Build();
AzureOpenAIChatCompletionService ai = new AzureOpenAIChatCompletionService("gpt-4-turbo", client);
ChatHistory history = new ChatHistory();
OpenAIPromptExecutionSettings settings = new() { ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions, ChatSystemPrompt = autopilotSystemMessage};
Console.Write("User: ");
string lastInput = Console.ReadLine();
while (lastInput != "exit")
{
history.AddUserMessage(lastInput);
ChatMessageContent result = await ai.GetChatMessageContentAsync(history, settings, kernel);
history.AddAssistantMessage(result.ToString());
Console.WriteLine($"Assistant: {result}");
Console.Write("User: ");
lastInput = Console.ReadLine();
}
}
And that is it. 30 lines, same functionality. As the loop of Functions is hidden inside the InvokePromptAsync of the kernel, enabled by "FunctionCallBehavior = FunctionCallBehavior.AutoInvokeKernelFunctions", there is less information played back to the user compared to the first approach. With every function call, OpenAI might also send a message to the user as well, which is hidden here, and we only get the message from the last function call result. But that is a small hill to die on compared to the days of time saved not having to code and test the rest manually.
Generic tricks
Before looking deeper into SK, lets wrap the use case up by implementing some good practises.
Reducing API returned data
How much an LLM call costs you and how long it will take is directly influenced by the Tokens a call will inference (in + out). While i have yet to see consistent large outputs from LLMs, i have seen very large inputs into LLMs. In the case of calling Functions, and those functions calling APIs, the input for the next round of the LLM is the output of the API, Azure Table ODATA in this case. It is therefore in our self interest to keep the Tokens as sparse as possible without loosing important information. The Azure Table API returns XML, and not just that: it also returns a lot of metadata that is not important to our endeavor. The solution: clean up the data before it reaches the ears of the LLM by removing unnecessary metadata and changing the format to a more token friendly format: JSON.
This is how i cleaned up the Azure Table Data specifically:
internal class AzureTableOdataCleaner : IDataCleanuper
{
public string Cleanup(string data)
{
XDocument doc = XDocument.Parse(data);
XNamespace d = "http://schemas.microsoft.com/ado/2007/08/dataservices";
XNamespace m = "http://schemas.microsoft.com/ado/2007/08/dataservices/metadata";
List<Dictionary<string, string>> entries = new List<Dictionary<string, string>>();
foreach (var entry in doc.Descendants(m + "properties"))
{
Dictionary<string, string> properties = new Dictionary<string, string>();
foreach (var prop in entry.Elements())
{
properties[prop.Name.LocalName] = prop.Value;
}
entries.Add(properties);
}
return System.Text.Json.JsonSerializer.Serialize(entries);
}
}
We load the XML into an XDocument, save the actually important information into a Dictionary, and return the serialized Dictionary. Other APIs possibly require a different approach. Using this, i was able to reduce the Token amount from 480 Tokens for a single result with 5 columns to 98 Tokens. This might get reduced further if you get rid of the special characters in JSON like "{" and "}", as they are a token each, and JSON has plenty of those. After all, the data does not have to be schema-perfect, it just needs to be there.
Cleaning up the History
One of the challenges everyone had to tackle before the Assistants API came along and does that for you. The problem is: As the chat history grows, so does your token inference, as the history is send with each and every request to the LLM. The easiest approach to solve this is to make a hard cut, for example only keeping the newest 10 messages. I want to present a more elaborate approach: have a limit in Tokens instead of Messages. Code:
private static async Task ReduceContextSize(List<ChatRequestMessage> messages)
{
const int tokenThreshold = 3000;
const int preserveAmount = 4; // Preserve the latest messages, as they provide the most important context
int contextSize = await GetContextSize(messages);
int removeCounter = 0;
while (contextSize > tokenThreshold && messages.Count > preserveAmount)
{
messages.RemoveAt(1); // do not remove the system message or the llm will be wildly confused
removeCounter++;
contextSize = await GetContextSize(messages); // Update context size after removal
}
if (removeCounter > 0)
{
Console.WriteLine($"[Cleanup] Context size was above threshold. Removed {removeCounter} messages, now the context size is {contextSize}");
}
}
private async static Task<int> GetContextSize(List<ChatRequestMessage> messages)
{
string allText = string.Empty;
foreach (var message in messages)
{
if(message is ChatRequestUserMessage messageUserMessage )
{
allText += messageUserMessage.ToString();
}
if(message is ChatRequestSystemMessage systemMessage && !string.IsNullOrEmpty(systemMessage.Content))
{
allText += systemMessage.Content.ToString();
}
if(message is ChatRequestAssistantMessage assistantMessage && !string.IsNullOrEmpty(assistantMessage.Content))
{
allText += assistantMessage.Content.ToString();
}
if(message is ChatRequestToolMessage toolMessage && !string.IsNullOrEmpty(toolMessage.Content))
{
allText += toolMessage.Content.ToString();
}
}
int tokenCount = await CountTokens(allText);
return tokenCount;
}
private static async Task<int> CountTokens(string text)
{
var IM_START = "<|im_start|>";
var IM_END = "<|im_end|>";
var specialTokens = new Dictionary<string, int>{
{ IM_START, 100264},
{ IM_END, 100265},
};
var tokenizer = await TokenizerBuilder.CreateByModelNameAsync("gpt-4", specialTokens);
var encoded = tokenizer.Encode(text, new HashSet<string>(specialTokens.Keys));
return encoded.Count;
}
Here we define a static threshold of tokens as well as a number of messages to preserve. What happens is that if you have many small messages going back and forth those will all be part of the context, allowing the LLM to have knowledge about messages that are longer ago. At the same time, if we have some realy big chunkers of messages, like many way too big API calls, we only preserve the newest, as they are the most important, removing the older big messages from the history as soon as they age. This code is for Azure.AI.OpenAI. Doing the same for SK is similar:
private async static Task<int> GetContextSize(ChatHistory history)
{
string allText = string.Empty;
foreach (var message in history)
{
allText += message.Content;
}
int tokenCount = await CountTokens(allText);
return tokenCount;
}

What else is there in SK?
Besides supporting the basic function calling loop SK has many other features not discussed with this specific usecase.
-SK provides access to not only OpenAI, but aims to provide access to all LLMs, which can be from Mistral, Anthropic, Google, Meta or locally hosted models ("Ollama"), while providing you with the same developer experience. Next to LLMs they also want to support multi-modal models, which will include images, videos and sound (coming 2024 afaik).
-Next to simple LLM calls, they plan to upgrade the Agent-Experience, similar to AutoGen but in .NET, at your C# fingertips.
-Not planned but implemented are planners. Any other LLM that is not from OpenAI does not have the same function calling, needing you to implement something like that yourself (like this for example: How to do Function Calling with any Chat LLM (that is clever enough) (jenscaasen.cloud)) or you can use SK. Using an OpenAI endpoint with the planners instead of the OpenAI Function calling may also provide benefits, but i did not try that enough to make that comparison.
-If you have random places in your code with prompts flying around then SK has semantic functions for you. On top of that, another team at MS is building a "Store" for prompts as part of the Azure AI Platform. Semantic functions are like prompts but reusable and chainable. You can give an initial input and have that input torn and twisted over multiple semantic functions, giving you the output only a list of prompts executed after another would give you, but automatically.
-As shown in this example, using native functions ("tools" in Azure.Ai.OpenAI) is a breeze. This allows you to extend your Agent / Bot / App with functionality beyond text in text out.
-One of my favorite parts of the SK package is Kernel Memory. KM is an ASP.NET service hostable in Azure that is your gateway to embeddings and vector databases. I've successfully tried it with Azure AI Search as Vector Database and it is an amazing way to keep way more information than you could ever fit into a prompt ready for usage. For example: you upload some PDF files, and the KM service extracts the text from them (cracking), creates chunks from the text, and creates embeddings for the chunks. Now your SK instance can use that KM service to search for specific information from those PDF files. Next to PDF they also support most office formats as well as images. It is as seamless as it sounds.
-Apart of self made native functions, which are functions that run code instead of a prompt, there is support for OpenAI Plugins as well as predefined Functions
Migration hints
This Guide is influenced by the fact that i mostly made Copilots, and are writing from that perspective. Your needs might differ or be more complex.
Instead of installing Azure.AI.OpenAI, install Microsoft.SemanticKernel
Instead of storing your History in a List<ChatRequestMessage>, store it in a ChatHistory. Bonus: ChatHistory is actually serializable, while ChatRequestMessages have the enum ChatRole, that can not be deserialized without hassle by System.Text.Json
Instead of settings the metadata like temperature to the LLM with ChatCompletionsOptions use OpenAIPromptExecutionSettings
Instead of using OpenAIClient use AzureOpenAIChatCompletionService (only for calls to OpenAI)
Instead of manually constructing and keeping a List of ChatCompletionsFunctionToolDefinition use builder.Plugins.AddFromObject / Type / Directory or use KernelPlugins
For Copilot builders: instead of creating a while (choice.FinishReason == CompletionsFinishReason.ToolCalls) or similar loop as shown in the Microsoft learn page, just run AzureOpenAIChatCompletionService.GetChatMessageContentAsync or similar
Conclusion
Using SK increases one's productivity compared to using the standard library Azure.AI.OpenAI or even the REST interface to (Azure)OpenAI by providing a robust implementation of LLM and Embedding specific workloads. My few projects i used this in so far got more stable and i was able to implement more features in less time. For me, however, SK was not easy to get into. This was due to many changes in the pre-v1 time, together with month' worth of blog posts and outdated documentations, which was downright confusing. I would guess that this is getting better now. The Kernel Memory is a massive timesaver if you do not want to put up with Vector-DB providers as weaviate, self hosted databases like Postgre SQL or other vector databases and the cracking, chunking and embedding of documents. Having a dedicated Team at Microsoft to keep up with connectors, planners, LLMs and new features is a big plus as well, but it could lead to a (short) delay in feature and service availability. The benefit of SK i put the most hope into is sharing of Plugins. Now Plugins can work across all LLMs, and everyone can make them in their favorite stack. This removes the need for everyone to create the same plugins. I can spend several days making and perfecting a bing-search-plugin, but Microsoft already made it, so why put in the effort, review the code and use it. Others might have already made a JIRA Plugin and battle-tested it, so i can use that time somewhere else.


