How to scale autonomous AI agents
Using Azure Durable Functions and OpenAPI Microservices to give tools to autonomous agents, cloud-native, at scale

I am a cloud-native developer at the international university of applied sciences, working mostly with Microsoft technology
Introduction
This is a follow-up post to the previous post that explored InProcess Function Calling with Reflection for smaller Workflows: How to do Function Calling with any Chat LLM (that is clever enough) (jenscaasen.cloud) The concepts here are similar, so reading the other blog post might be a good idea.
Here is a video showing the concept:
Why do you need scaling?
Let's assume we have a script. We can run that script, and it does its thing. Now someone else saw that and said "That is a good Script! I want to run it too!". At this point, you have to either let the other person use your computer, or the other person tells you how they want the script to be run and you do the work, or they install it on their machine. The first 2 options get you in conflict with your own script running, the last one works for 2 people, but what if the script changes? Then you need a process to update the script on their machine as well. And what if it's not 1 other person, but 2000 other people? This is where scalability is important. Luckily, there are companies with a lot of big houses full of computers, and they let you run your things there. And not just that, they also let you run your things 2,000 or more times in parallel, no matter how complex your things are.
Microservices vs. monolithic architecture with AI agents
I will not roll up the whole debate of those 2 principles, but add a perspective about autonomous agents. A lot of coding is outsourced to the inner workings of LLMs. The same software can rename a range of groups in an active directory as well as bake a cake, given the right connectors to do so. The need for logical coding is greatly reduced. What is left is coding connectors (tools). Given the fast pace with which the field is developing, and the fast pace with which new use cases with new connectors can give just another benefit to an agent, maintaining everything in a single deployment gives birth to problems with having a running instance and updating it, as well as scaling individual parts of it. An agent might need the "send email" tool just a few times a week while using the "search the web" tool every 5 minutes. Why scale the "send email" tool alongside the "search the web" tool?
Another problem with monolithic architecture is state management. Do you shut down your whole AI service to update some subprocess, or do you just update the subprocess and leave the AI service alone, running its loop, and having a retry or 2 on the updated subprocess?
Scaling in Azure with durable functions
In Azure, and probably all other major cloud providers, you can scale VMs, runbooks (scripts), web applications and a lot of other backend systems. One of the basic methods of running code in Azure is Azure Functions, and they come with a nice extension from which autonomous agents can profit: durable functions. Durable functions are functions that get run every couple of seconds, but they save the state of function calls done in the code, therefore not running the same code again if it's not needed. To the front, this uses the async pattern, in which you start the process via HTTP, and then you have to poll for a result by yourself. This allows for very long-running workflows. Imagine having an agent using a "send email and wait for reply" tool. Someone replying to your E-Mail in 5 Minutes is utopian and would lead to an HTTP timeout in traditional function calling. Durable functions on the other hand save the state to a storage account, enabling someone to come back from vacation (or whatever people do when not answering E-Mails) and give needed input to the agent, which then continues its workflow as if nothing happened. Furthermore, durable functions are not limited to running 1 instance: they can run thousands of instances in parallel.
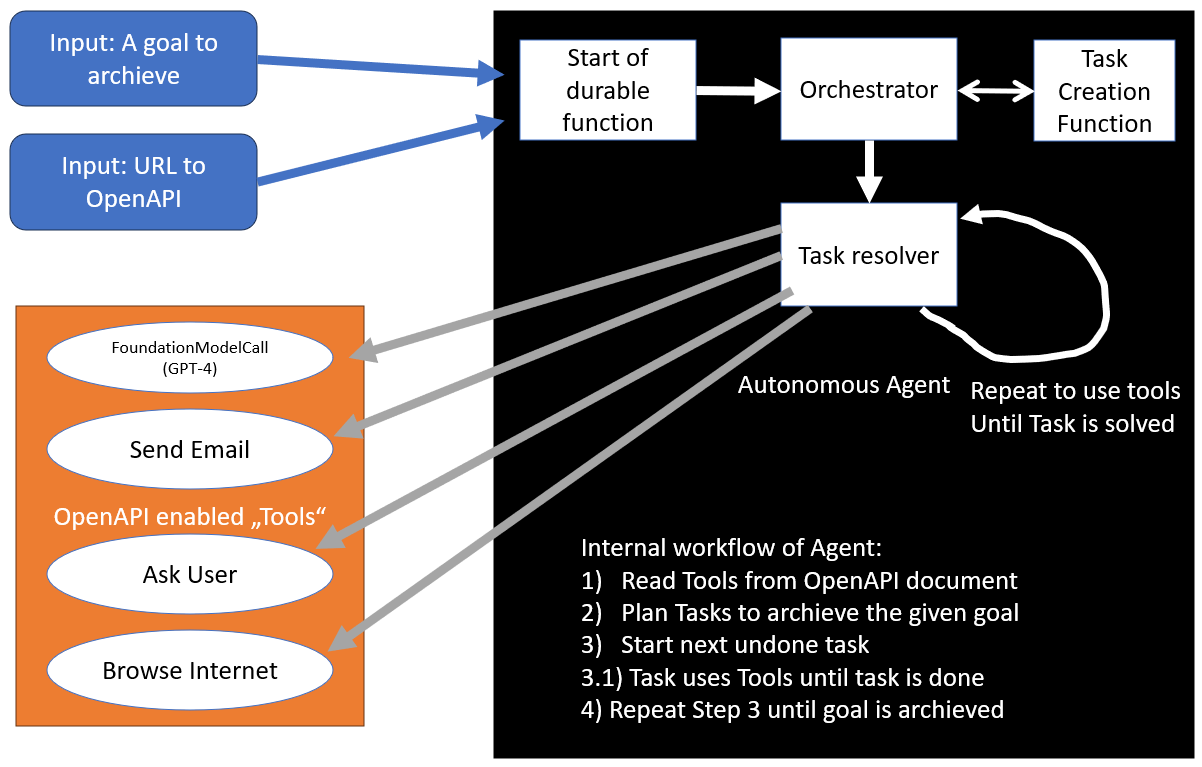
Concept of BabyAGI applied, but with dynamic tools
BabyAGI is one of the early proof-of-concepts of autonomous agents with LLM technology. They do not just have a 1:1 conversation with ChatGPT, but instead internal dialogues, using the API of OpenAI more like a tool and less like a service to talk to.
To use this in a serverless, cloud-native environment we need 1 durable function + X microservices, that do the actual work as "tools". To make the tools known to the agent, we can rely on OpenAPI specifications. They contain all the information needed: where do I find that tool (URL), how can I use it (parameters) and what does it do (Description)? The last 2 information are important for GPT-4 to decide when and how to use it, the first is important to our agent host. We can take this even a step further: an LLM is also a tool. Why not abstract the communication to the LLM as a tool as well? This enables us to switch the LLM at will without having to update anything on the agent. It also allows the sharing of credentials to LLMs across different products. And lastly, it makes logging easier. So instead of holding an OpenAI / Azure OpenAI / Anthropic key ready at the agent, we can outsource this as a tool in the toolbelt we hand over to the agent.
This toolbelt, in our case an OpenAPI definition, can be hosted separately, in an Azure Function for example, or a Asp.net service.
Using BabyAgi's main loop, implemented as cloud native c# application, we can now create tasks based on the goal and let GPT-4 figure out what tools to use for each task.